Emby muss seine Daten ja irgendwo speichern. Warum sollte es also nicht möglich sein, auch ohne die Emby-GUI in die Daten zu schauen? Irgendwo hatte ich gelesen, dass es sich um eine SQLite-Datenbank handelt, die die Daten verwaltet. Nach kurzer Recherche wurde klar, dass die relevante Datei library.db ist.
Läuft Emby auf einem aktuellen Synology-NAS, stößt man hier auf ein erstes Hindernis. Die Daten der App-Installationen ist nicht mehr so einfach zu erreichen. Um trotzdem an die Daten zu kommen, gibt es sicherlich viele Wege.
1.) in Emby ein Backup (Backup&Restore) einrichten. Hier kann man ein Zielverzeichnis wählen, dass auf normalem Weg zu erreichen ist. Ist aber langweilig und: es wird das gesamte Anwendungsverzeichnis gesichert. Das ist mir zuviel.
2.) Eine Möglichkeit finden, schnell und einfach via GUI auf die Daten zuzugreifen: Root File Browser
3.) Einen Backupjob einrichten, der nur die Datei library.db sichert. Idealerweise sehr leicht erreichbar.
Root File Browser auf Synology einrichten
Folgt bitte meiner Anleitung zur Einrichtung des Root File Browsers
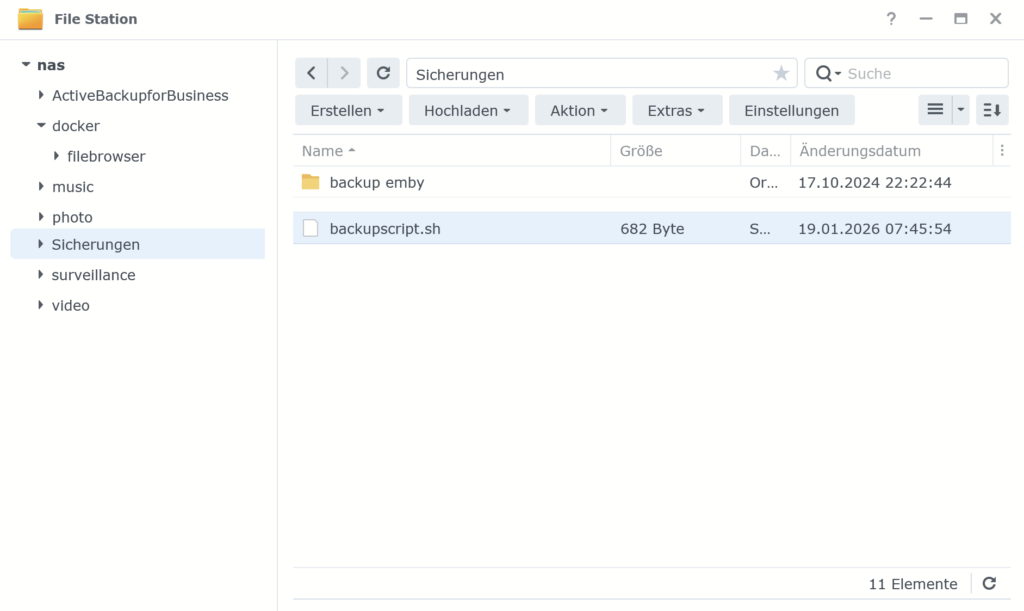
Nun könnt ihr in das Verzeichnis /volume1/@appdata/EmbyServer/data browsen und euch die Datei library.db herunterladen:
Backupjob für library.db nach google drive einrichten
Dieser Weg hat mir irgendwie am besten gefallen. Dazu habe ich die folgende kleine Anleitung geschrieben.
Wenn du die Datei über das Backupscript gesichert hast, dann muss die Datei zuerst entpackt werden. In diesem Fall geht das mit 7zip.
Auswerten der Library.db
Es handelt sich, wie bereits erwähnt, um eine SQLite-Datenbank. Zur Auswertung einer solchen DB bieten sich diverse Wege an. Der für mich komfortabelste ist der SQLite-Browser:
ladet also https://sqlitebrowser.org/dl/ herunter.
Mit diesem Programm kann man nun die Datei library.db öffnen. Dort finden wir eine ganze Menge Tabellen. Zur Orientierung für euch empfehle ich die Tabellen Mediaitems und Mediastreams2. In die Tabellen kann man einfach so reinschauen. Die Datenbank (um ein solche handelt es sich) bietet den Vorteil, SQL-Abfragen zu definieren, die einem dann eine tolle Auswertungsmöglichkeit gibt. Ich habe für meinen Fall folgendes Select zusammengestellt.
select distinct items.name, items.OriginalTitle, ProductionYear
from mediastreams2 streams, mediaitems items
where (lower(streams.title) like '%kommentar%' or lower(streams.title) like '%commentary%')#####
and streams.itemid = items.id
and items.type=5
order by lower(items.name)Diese Abfrage liefert mir alle Filme, in denen es Audiostreams gibt, die den Begriff „Kommentar“ oder „commentary“ enthalten.
Einen Überblick verschaffen kann man sich mit
select path, OriginalTitle, name, type from MediaItems order by typeWir finden dort beispielsweise folgende Typen:
- Type 3 Verzeichnisnamen
- Type 4 Libraries
- Type 5 Filme
- Type 6 Serien
- Type 8 Episodes
- Type 11 musik tracks
- Type 12 Hörbücher
- Type 13 Musik/Hörbuch-Interpreten
- Type 23 Cast & Crew
- Type 25 Fotos
Viel Spaß beim Erkunden